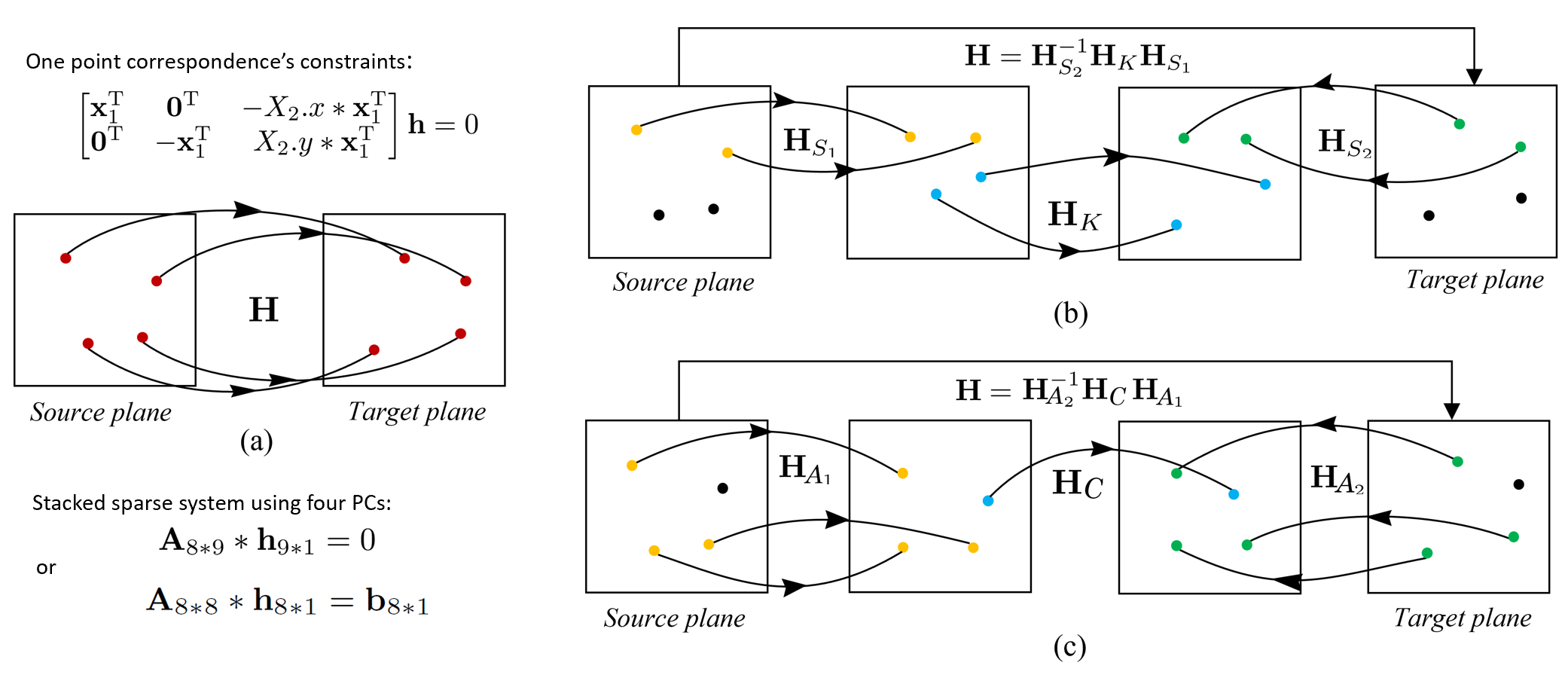
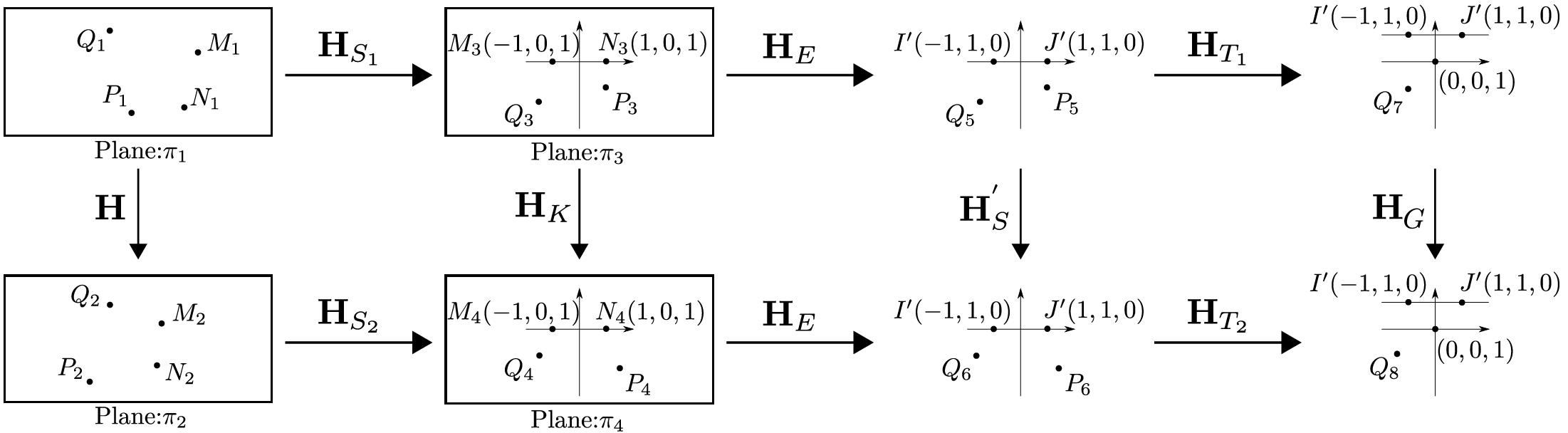
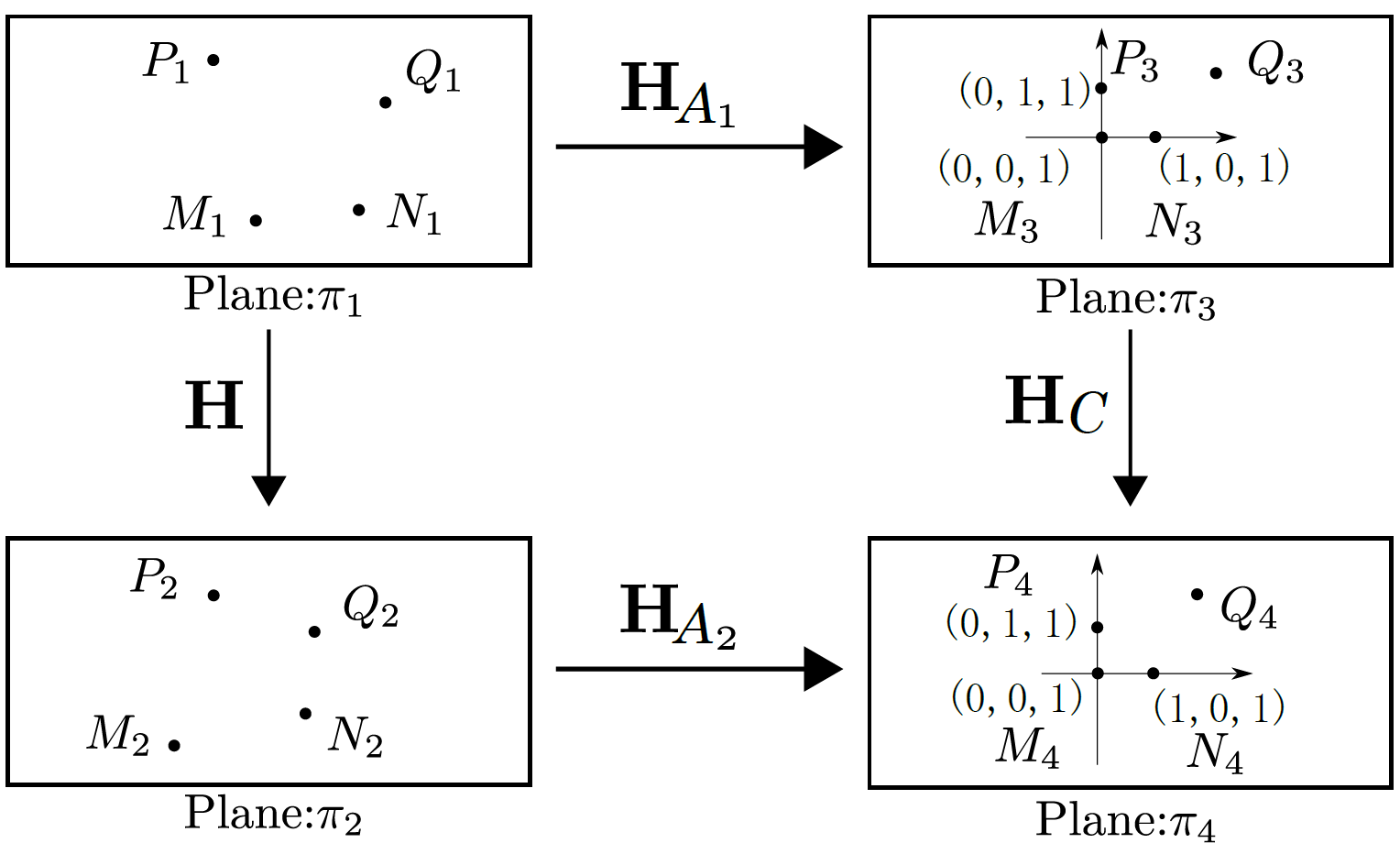
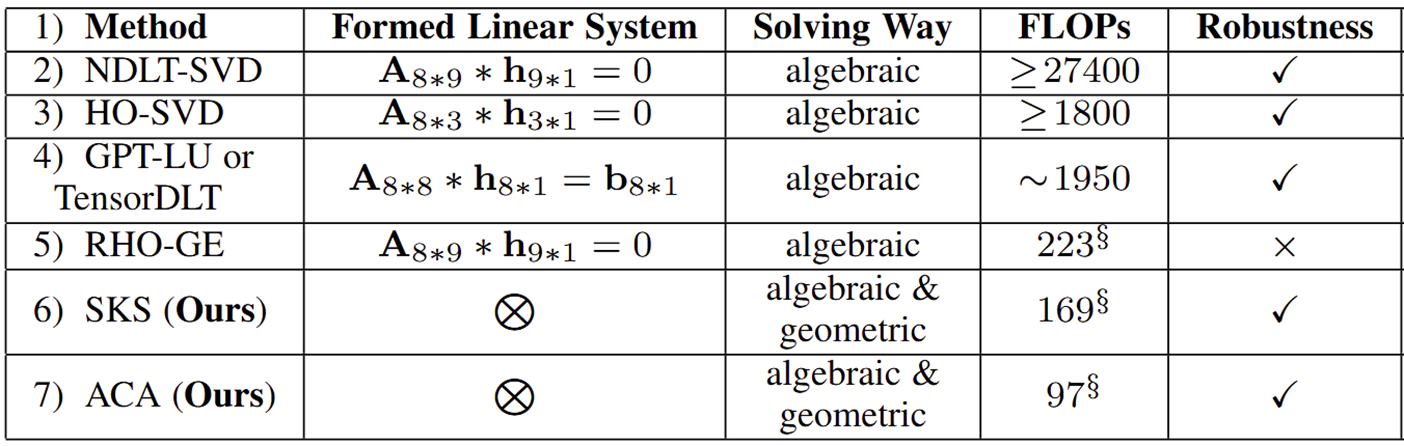
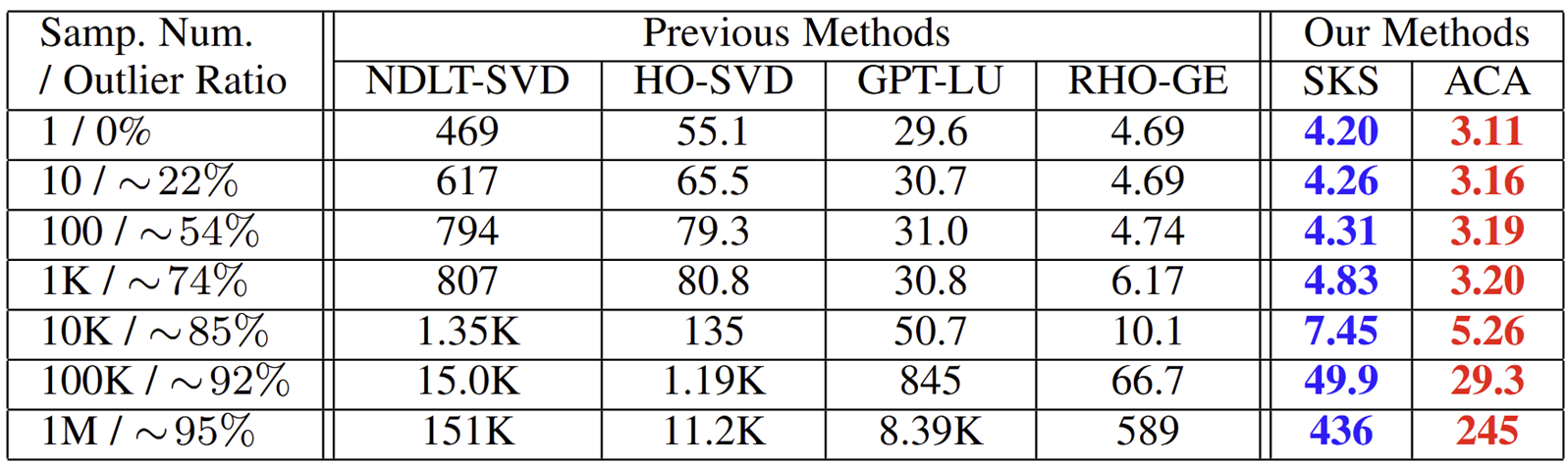
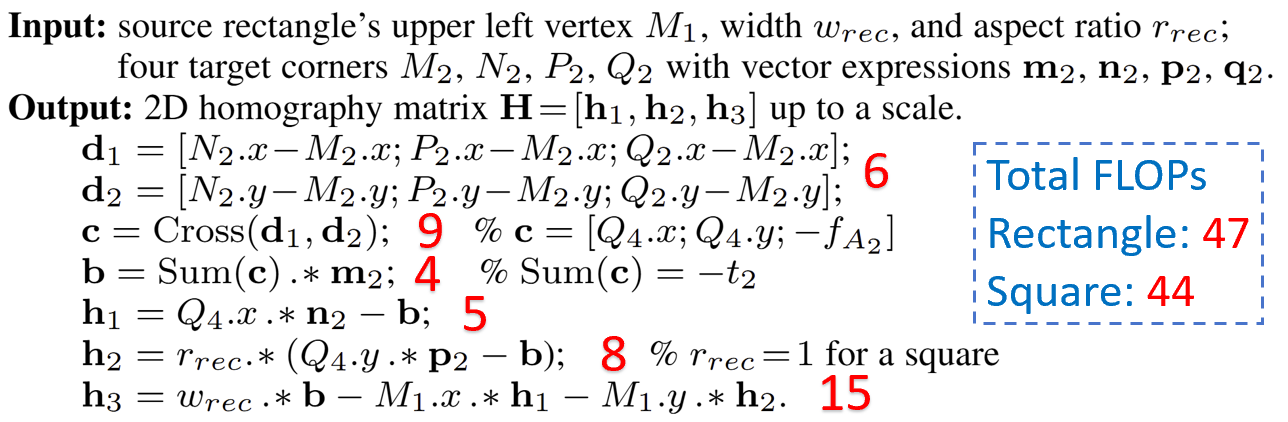Core Idea
Previous 4-point homography methods indiscriminately utilize all four point correspondences to construct a sparse linear system, using the Direct Linear Transformation (DLT) strategy, as shown in (a). This system (with many 0s and 1s) is typically solved by standard matrix factorization techniques like LU decomposition based on Gaussian elimination. In contrast, our Similarity-Kernel-Similarity (SKS) and Affine-Core-Affine (ACA) decomposition tackle the homography geometrically, as depicted in (b) and (c). SKS uses two point correspondences (yellow and green) to estimate the two involved similarity transformations, while ACA employs three for affine transformations. The remaining points (blue) in each case address the residual projective distortion.